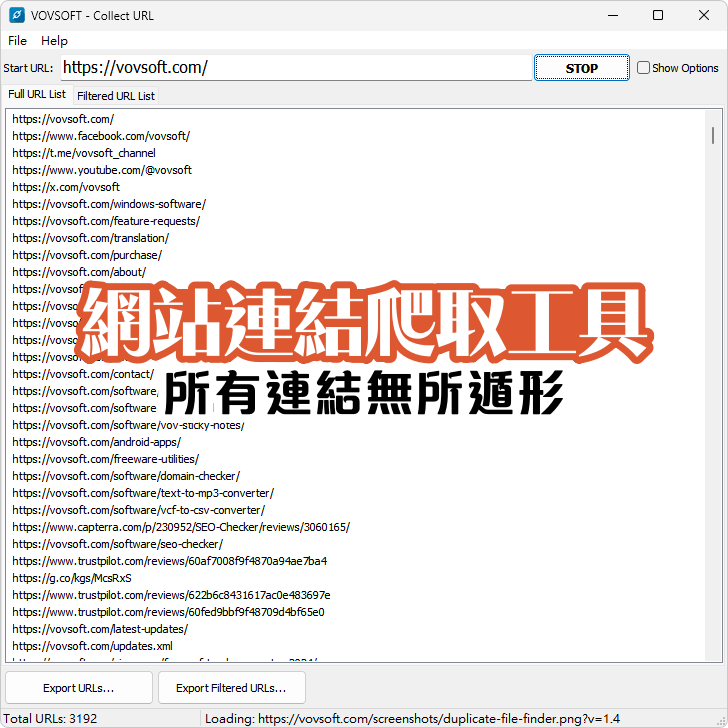
定時抓網頁
2024年6月13日—網站爬蟲是一個專為網頁抓取而設計的擴充功能。輕鬆地抓取網站並輕鬆地利用數據抓取。網站爬蟲簡化了如何爬取網站並將網絡數據爬取轉化為一項簡單的 ...,...單元17、如何設定自動抓取網頁.3分鐘·第三章節、Python爬蟲實務.單元18、如何繞掉網頁驗證碼...
在实现爬虫的任务时,有时需要满足定时爬取网页内容的相关功能,那么本实例将通过Python代码来实现一个简单的定时爬虫任务。*代码实现.在实现定时爬取网页内容时,首先需要 ...
** 本站引用參考文章部分資訊,基於少量部分引用原則,為了避免造成過多外部連結,保留參考來源資訊而不直接連結,也請見諒 **
網站爬蟲
2024年6月13日 — 網站爬蟲是一個專為網頁抓取而設計的擴充功能。輕鬆地抓取網站並輕鬆地利用數據抓取。 網站爬蟲簡化了如何爬取網站並將網絡數據爬取轉化為一項簡單的 ...
如何定時爬取網頁更新資訊
... 單元17、如何設定自動抓取網頁. 3分鐘 · 第三章節、Python 爬蟲實務. 單元18、如何繞掉網頁驗證碼. 4分鐘 · 第三章節、Python 爬蟲實務. 單元19、如何大量爬取單一頁面. 4 ...
Python爬虫练习二
2020年6月4日 — 2. 网络爬虫:利用requests和BeautifulSoup库抓取网页数据,进行数据分析。 3. 数据可视化:使用matplotlib或seaborn库绘制图表,理解数据分布和趋势 ...
輕鬆學習Python:定時執行網站爬蟲. 以AWS EC2
2019年6月9日 — 在這個小節中我們簡介如何以Python 的 requests 、 beautifulsoup4 套件擷取網頁資料; pandas 、 sqlite3 套件寫入SQLite 資料庫,並且整合成為一個爬蟲 ...
動態網頁爬蟲
2024年5月31日 — 從網頁伺服器下載JavaScript程式碼,在客戶端執行後產生內容。 · 透過客戶端的需求,在伺服器端產生內容後,以AJAX(Asynchronous JavaScript And XML)技術下載 ...
20個網頁抓取工具快速抓取網站
Getleft是一款免費且易於使用的網站抓取工具。它允許您下載整個網站或任何單個網頁。啟動Getleft後,您可以輸入URL並在開始之前選擇要下載的文件。雖然 ...
实现定时爬取网页内容 - 程序开发资源库
在实现爬虫的任务时,有时需要满足定时爬取网页内容的相关功能,那么本实例将通过Python代码来实现一个简单的定时爬虫任务。 * 代码实现. 在实现定时爬取网页内容时,首先需要 ...