Crawlbase lets you scrape and crawl data anonymously and store it in the cloud. Our web scraping and crawling API handles browsers and CAPTCHAs with a ...
2024年3月15日 — 1. Check robots exclusion protocol · 2. Use a proxy server · 3. Rotate IP addresses · 4. Use real user agents · 5. Set your fingerprint right · 6.
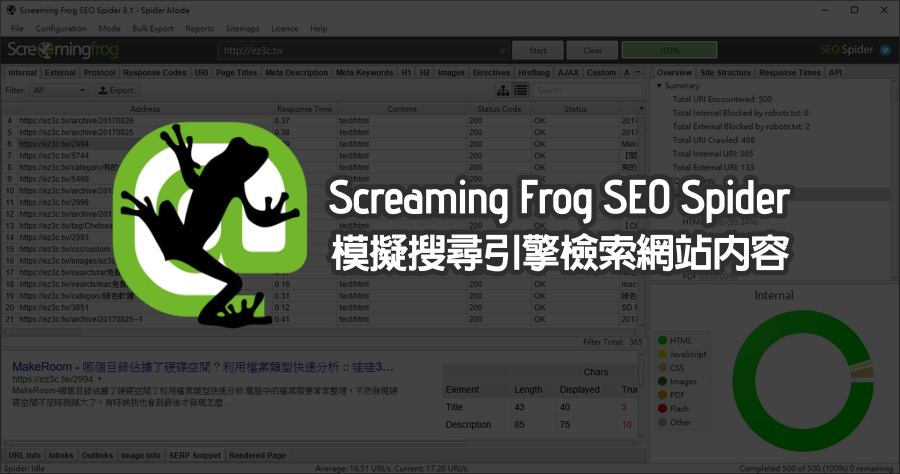
2024年8月22日 — A web crawler, web spider, or crawler is a program that searches and automatically indexes web content and other data over the web. Web crawlers ...
2024年9月18日 — Octoparse is known as the best web crawler which is a client based tool used to get the data into the spreadsheets. It is built for non coders.
2023年9月11日 — Manual copy and paste. The most straightforward way to scrape data from a website is to manually copy data from the source and analyze it.